
The algorithms meant to make life easy could further divide us if we're not paying attention
By Justin Lehmann, Marketing Coordinator
The current moment is asking us to evaluate almost every systemic issue in our society. While it might be uncomfortable, the only way through it is to look at the systems that control who wins and who loses and ask, "are they biased?"
It's convenient to think that our work in technology is above these issues. A lot of folks in tech do this work to change the world or help communities in need. But just like the rest of society, we need to take this moment of self-reflection seriously, lest our failures are judged by the next generation as harshly as we're judging our elders now.
There are larger issues like discrimination in tech hiring, and complaints of racist and misogynistic acts going unanswered from the upper echelons of tech companies that will need to be addressed at a company level. What we wanted to talk about today is the discrimination developers are inadvertently injecting into the algorithms that run our lives.
We wanted to reignite this discussion because at Exyn we're constantly building and evaluating artificial intelligence and machine learning algorithms ourselves. One area we've had to stay hyper-vigilant is in our object detection and avoidance. We're teaching our robots how to identify people so they can navigate safely around them. But if the model for "person" only represents tall, slender Anglo-Saxon men we'd be unintentionally programming our robots to be less safe around large swaths of the global population. If we didn't take these considerations while creating the algorithm, we might not even know there even was a problem until the robot started exhibiting unintended behaviors in the field.
The word itself has transformed from tech lingo to something more akin to magic or religion. It's some big amorphous blob that controls what social media we consume, how much we get charged for an Uber, who gets arrested, who can get a job, how much we'll pay for rent or a mortgage, and probably so many other things we don't even consider.
Whenever I hear someone complaining about being cheated by the algorithm, I think of the control panel in the TARDIS from the British TV show, Doctor Who (I know, I'm a huge nerd). Various unlabeled knobs, buttons, and levers that are flipped, pushed, and twisted until the ship magically arrives at the exact destination The Doctor intended. How did it get there? ♂️ It's the algorithm!

However, algorithms aren't magic. They're human opinions wrapped in code.
An algorithm is a set of mathematical steps that gets you from a question to an answer, taking shortcuts or looking things up as needed. At first, algorithms were used to help number crunch monumental proofs like the traveling salesman problem. But since the advent of big data and deep learning, algorithms are used as a method for distilling huge amounts of "training data" into patterns that can be used to make predictions about new input. So even the most altruistic algorithm, if fed biased training data, will produce a biased result.
In her work that is more relevant than ever, Cathy O'Neil addresses the fundamental flaw we have when discussing the algorithms we use in technology to improve our societies. We are taught to trust math, but also fear it. How many times has someone told you, "it's just math, you wouldn't understand, don't worry about it." Too often those that create algorithms hide behind those words -- or the fact that their IP is a "secret sauce" -- so as to avoid discussing the roots of how the algorithms were created.
But algorithms don't have to be complicated. You just need data and the desired outcome. O'Neil explains the algorithm she uses every day to make food for her family. The data is the food available, how much time she has, the motivation to cook, etc. And the desired outcome is her kids eating some amount of vegetables. Sounds like a great algorithm! But if you were to ask her kids, their desired outcome might be different.
The issue is that humans are hard-wired with biases. And even when we try to strip those biases away when building algorithms to improve our lives and society around us, they can still creep back in through the data we choose to incorporate, and the outcomes we view as favorable.
One great example of an algorithm gone wrong is O'Neil's work investigating the Value-Added Model that was used to evaluate teachers’ performance. Teachers have been fired for bad scores and many teacher protests stemmed from how much that data is used in evaluating their work and future career path. When O'Neil tried to find the formula behind this model, she was shut down. She was told, "it's all math, you wouldn't understand it." Sound familiar?
Even the Department of Education couldn't get their hands on the model, but it was being used all over the country. Our only glimpse into the model was through newspapers getting access to teachers' scores and -- perhaps wrongly -- publishing them. One enterprising high school math teacher, Gary Rubinstein, took 13,000 of those scores and plotted them, with 2009 scores on the x-axis and 2010 scores on the y-axis. If the data was consistent, he said, "one would expect some kind of correlation with points clustered on an upward sloping line." Here's what he got:
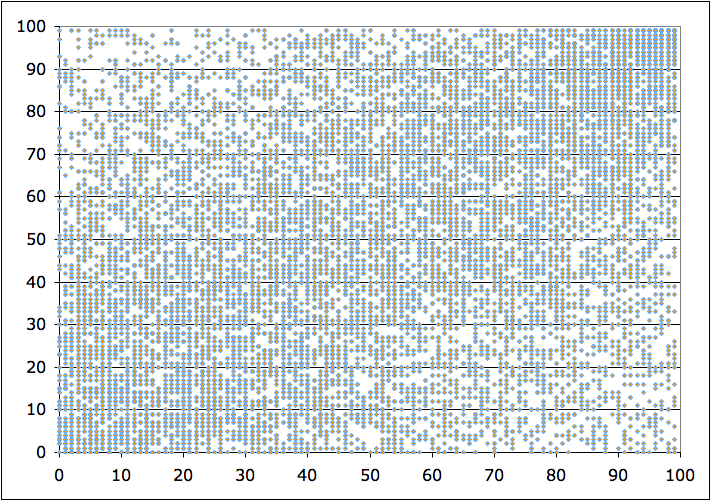
The plot shows extremely low correlations between the two scores when most teachers tell you there's general improvement year after year. You can observe that about 50% of the teachers' scores do go up, which some would qualify as "most teachers" but as Rubinstein notes, you'd likely get the same results from a random number generator. Not a finely tuned algorithm.
While it seems silly to get so worked up over teacher evaluations, it doesn't take long to see how a simple score can change entire neighborhoods. Because while the Value Added Model punished teachers for low scores, it also handed out bonuses for high ones. In her research, O'Neil found that some teachers were cheating -- artificially increasing their students' scores -- to give themselves higher marks. And when those students moved on, their new teachers were left with underprepared students who were ranked higher according to the model.
So while the model might rank a student at a 95, the reality would be closer to an 80. Meaning even if they scored a 90 under their new teacher -- a 10 point increase in reality -- the model would see that as a 5 point decline and lower the teacher's rank. I can't imagine how frustrating this must be for teachers, and also for parents who don't understand why the teachers aren't helping. That frustration can lead to a lack of trust in institutions, lack of interest in schooling, and gross misappropriation of much-needed funds and resources.
In a more recent example, Robert Williams was at work when the police called and demanded he turn himself in for robbery. He thought it was a co-worker pranking him. Later, he was arrested at home in front of his family and held by police for 30+ hours for a crime he didn't commit. So why did the police arrest and question him with such certainty? Facial recognition identified him as a potential match for a recent count of theft.

Now, the companies that produce facial recognition technology will tell you that they're providing potential suspects to police and not identifying exactly the person who committed the crime. But when you hear police talking about facial recognition, they treat it like a “truth machine”. The computer can't be wrong, right? Actually, when researchers tested these systems, they've found that the computer can be wrong almost 96% of the time. And when you add race into the equation, turns out it's wrong almost every time.
This isn't to say that every single algorithm is flawed and evil. There are some good, hard-working algorithms out there! But how can we recognize and fix the algorithms that are broken while also re-engineering the ones running throughout our society?
Firstly, it's time that data scientists creating models truly think about the impact algorithms have on people's lives. Maybe that means we take an oath like a doctor and pledge to first do no harm through the algorithms we create. It also means carefully evaluating the data we're feeding into algorithms and bringing more diversity into the creation of these models, to begin with.
Second, we need to create tools to audit algorithms in the wild. Algorithms are just automating the systems that have worked for us in the past, and we're not going to make sweeping structural changes with a "set it and forget it" mindset. We'll need to build regulatory algorithms that can alert us to misbehaving machine learning so we can adjust the desired outcomes to be more broadly beneficial.
Lastly, we need a consumer bill of rights. Just like how you can check your credit score when applying for a mortgage or leasing a car, we need to be able to see behind the curtain and check the scores these algorithms are assigning to us. And if we find them flawed there needs to be a regulatory body that can enact change.
If you work in tech you might be aware of the term technical debt. For the uninitiated, technical debt is a measure of potential problems in your software. If you have an important piece of code that you keep patchworking, the technical debt increases because should things go sideways it will take tremendous effort to fix it. Whereas if you invest your time wisely while writing code, you'll have less technical debt to deal with in the future.
We have a big technical debt problem in our society. That's why it feels like we're trying to solve every societal ill in one weekend. We've let our debt accumulate for generations, passing patchwork legislation to dole out human and civil rights, often with strings attached. We've ignored whole sections of our society trying to point out cracks in the system our most vulnerable fall into. And we've allowed the larger algorithms that run our society to reward the cheaters and punish those trying to do better.
We have an important choice to make: we can find a patchwork solution to keep the lights on until the next kernel panic, or we can put in the work to build a society that can benefit everyone without crashes or panics. It's going to take a lot of work, but the best part about working in technology is that most people you work with want to change the world for the better. So you won't be alone.
